Tutorial
torchquad is a dedicated module for numerical integration in arbitrary dimensions. This tutorial gives a more detailed look at its functionality and explores some performance considerations.
Minimal working example
# To avoid copying things to GPU memory,
# ideally allocate everything in torch on the GPU
# and avoid non-torch function calls
import torch
from torchquad import MonteCarlo, set_up_backend
# Enable GPU support if available and set the floating point precision
set_up_backend("torch", data_type="float32")
# The function we want to integrate, in this example
# f(x0,x1) = sin(x0) + e^x1 for x0=[0,1] and x1=[-1,1]
# Note that the function needs to support multiple evaluations at once (first
# dimension of x here)
# Expected result here is ~3.2698
def some_function(x):
return torch.sin(x[:, 0]) + torch.exp(x[:, 1])
# Declare an integrator;
# here we use the simple, stochastic Monte Carlo integration method
mc = MonteCarlo()
# Compute the function integral by sampling 10000 points over domain
integral_value = mc.integrate(
some_function,
dim=2,
N=10000,
integration_domain=[[0, 1], [-1, 1]],
backend="torch",
)
To set the default logger verbosity, change the TORCHQUAD_LOG_LEVEL
environment variable; for example export TORCHQUAD_LOG_LEVEL=DEBUG.
A later section in this tutorial shows how
to choose a different numerical backend.
For information on using multiple GPUs, see the Multi-GPU Usage section.
Detailed Introduction
The main problem with higher-dimensional numerical integration is that the computation simply becomes too costly if the dimensionality, n, is large, as the number of evaluation points increases exponentially - this problem is known as the curse of dimensionality. This especially affects grid-based methods, but is, to some degree, also present for Monte Carlo methods, which also require larger numbers of points for convergence in higher dimensions.
At the time, torchquad offers the following integration methods for abritrary dimensionality.
Name |
How it works |
Spacing |
|---|---|---|
Trapezoid rule |
Creates a linear interpolant between two |
Equal |
Simpson’s rule |
Creates a quadratic interpolant between |
Equal |
Boole’s rule |
Creates a more complex interpolant between |
Equal |
Gaussian Quadrature |
Uses orthogonal polynomials to generate a grid of sample points along with corresponding weights. A GaussLegendre implementation is provided as is a base Gaussian class that can be extended e.g., to other polynomials. |
Unequal |
Monte Carlo |
Randomly chooses points at which the |
Random |
VEGAS
Enhanced
|
Adaptive multidimensional Monte Carlo |
Stratified
|
Outline
This tutorial is a guide for new users to torchquad and is structured in the following way:
Example integration in one dimension (1-D) with PyTorch
Example integration in ten dimensions (10-D) with PyTorch
Some accuracy / runtime comparisons with scipy
Information on how to select a numerical backend
Example showing how gradients can be obtained w.r.t. the integration domain with PyTorch
Methods to speed up the integration
Multidimensional/Vectorized Integrands
Parametric Integration with Variable Domains
Custom Integrators
Feel free to test the code on your own computer as we go along.
Imports
Now let’s get started! First, the general imports:
import scipy
import numpy as np
# For benchmarking
import time
from scipy.integrate import nquad
# For plotting
import matplotlib.pyplot as plt
# To avoid copying things to GPU memory,
# ideally allocate everything in torch on the GPU
# and avoid non-torch function calls
import torch
torch.set_printoptions(precision=10) # Set displayed output precision to 10 digits
from torchquad import set_up_backend # Necessary to enable GPU support
from torchquad import Trapezoid, Simpson, Boole, MonteCarlo, VEGAS # The available integrators
from torchquad.utils.set_precision import set_precision
import torchquad
# Use this to enable GPU support and set the floating point precision
set_up_backend("torch", data_type="float32")
One-dimensional integration
To make it easier to understand the methods used in this notebook, we will start with an example in one dimension. If you are new to these methods or simply want a clearer picture, feel free to check out Patrick Walls’ nice Python introduction to the Trapezoid rule and Simpson’s rule in one dimension. Similarly, Tirthajyoti Sarkar has made a nice visual explanation of Monte Carlo integration in Python.
Let f(x) be the function 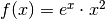 . Over the domain
. Over the domain
![[0,2]](_images/math/8a1d0f43efe3dfb2b95c1c0837f58da35899be78.png) , the integral of
, the integral of f(x) is 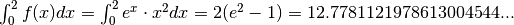
Let’s declare the function and a simple function to print the absolute error, as well as remember the correct result.
def f(x):
return torch.exp(x) * torch.pow(x, 2)
def print_error(result, solution):
print("Results:", result.item())
print(f"Abs. Error: {(torch.abs(result - solution).item()):.8e}")
print(f"Rel. Error: {(torch.abs((result - solution) / solution).item()):.8e}")
solution = 2 * (torch.exp(torch.tensor([2.0])) - 1)
Note that we are using the torch versions of functions like ``exp`` to ensure that all variables
are and stay on the GPU.
Also, note: the unit imaginary number 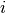 is written as
is written as j in Python.
Let’s plot the function briefly.
points = torch.linspace(0, 2, 100)
# Note that for plotting we have to move the values to the CPU first
plt.plot(points.cpu(), f(points).cpu())
plt.xlabel("$x$", fontsize=14)
plt.ylabel("f($x$)", fontsize=14)
Let’s define the integration domain, set the precision to double, and initialize the integrator - let’s start with the trapezoid rule.
# Integration domain is a list of lists to allow arbitrary dimensionality.
integration_domain = [[0, 2]]
# Initialize a trapezoid solver
tp = Trapezoid()
Now we are all set to compute the integral. Let’s try it with just 101 sample points for now.
result = tp.integrate(f, dim=1, N=101, integration_domain=integration_domain)
print_error(result, solution)
Output: Results: 12.780082702636719
Abs. Error: 1.97029114e-03
Rel. Error: 1.54192661e-04
This is quite close already, as 1-D integrals are comparatively easy. Let’s see what type of value we get for different integrators.
simp = Simpson()
result = simp.integrate(f, dim=1, N=101, integration_domain=integration_domain)
print_error(result, solution)
Output: Results: 12.778112411499023
Abs. Error: 0.00000000e+00
Rel. Error: 0.00000000e+00
mc = MonteCarlo()
result = mc.integrate(f, dim=1, N=101, integration_domain=integration_domain)
print_error(result, solution)
Output: Results: 13.32831859588623
Abs. Error: 5.50206184e-01
Rel. Error: 4.30584885e-02
vegas = VEGAS()
result = vegas.integrate(f, dim=1, N=101, integration_domain=integration_domain)
print_error(result, solution)
Output: Results: 21.83991813659668
Abs. Error: 9.06180573e+00
Rel. Error: 7.09166229e-01
Notably, Simpson’s method is already sufficient for a perfect solution here with 101 points. Monte Carlo methods do not perform so well; they are more suited to higher-dimensional integrals. VEGAS currently requires a larger number of samples to function correctly (as it performs several iterations).
Let’s step things up now and move to a ten-dimensional problem.
High-dimensional integration
Now, we will investigate the following ten-dimensional problem:
Let f_2 be the function 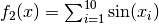 .
.
Over the domain ![[0,1]^{10}](_images/math/370e234cf8578770d214f644a035afc62553a4ba.png) , the integral of
, the integral of f_2 is
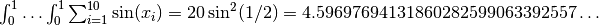
Plotting this is tricky, so let’s directly move to the integrals.
def f_2(x):
return torch.sum(torch.sin(x), dim=1)
solution = 20 * (torch.sin(torch.tensor([0.5])) * torch.sin(torch.tensor([0.5])))
Let’s start with just 3 points per dimension, i.e., 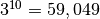 sample points.
sample points.
Note: torchquad currently only supports equal numbers of points per dimension. We are working on giving the user more flexibility on this point.
# Integration domain is a list of lists to allow arbitrary dimensionality
integration_domain = [[0, 1]] * 10
N = 3 ** 10
tp = Trapezoid() # Initialize a trapezoid solver
result = tp.integrate(f_2, dim=10, N=N, integration_domain=integration_domain)
print_error(result, solution)
Output: Results: 4.500804901123047
Abs. Error: 9.61723328e-02
Rel. Error: 2.09207758e-02
simp = Simpson() # Initialize Simpson solver
result = simp.integrate(f_2, dim=10, N=N, integration_domain=integration_domain)
print_error(result, solution)
Output: Results: 4.598623752593994
Abs. Error: 1.64651871e-03
Rel. Error: 3.58174206e-04
boole = Boole() # Initialize Boole solver
result = boole.integrate(f_2, dim=10, N=N, integration_domain=integration_domain)
print_error(result,solution)
Output: Results: 4.596974849700928
Abs. Error: 2.38418579e-06
Rel. Error: 5.18642082e-07
mc = MonteCarlo()
result = mc.integrate(f_2, dim=10, N=N, integration_domain=integration_domain, seed=42)
print_error(result, solution)
Output: Results: 4.598303318023682
Abs. Error: 1.32608414e-03
Rel. Error: 2.88468727e-04
vegas = VEGAS()
result = vegas.integrate(f_2, dim=10, N=N, integration_domain=integration_domain)
print_error(result, solution)
Output: Results: 4.598696708679199
Abs. Error: 1.71947479e-03
Rel. Error: 3.74044670e-04
Note that the Monte Carlo methods are much more competitive in this case. The bad convergence properties of the trapezoid method are visible while Simpson’s and Boole’s rule are still OK given the comparatively smooth integrand.
If you have been repeating the examples from this tutorial on your own computer, you
might get RuntimeError: CUDA out of memory if you have a small GPU.
In that case, you could also try to reduce the number of sample points (e.g., 3 per dimension).
You can really see the curse of dimensionality fully at play here, since 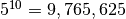 but , reducing the number of sample points by a factor of 165.
Note, however, that Boole’s method cannot work for only 3 points per dimension, so the number of sample points is therefore
automatically increased to 5 per dimension for this method.
but , reducing the number of sample points by a factor of 165.
Note, however, that Boole’s method cannot work for only 3 points per dimension, so the number of sample points is therefore
automatically increased to 5 per dimension for this method.
Comparison with scipy
Let’s explore how torchquad’s performance compares to scipy, the go-to
tool for numerical integration. A more detailed exploration of this
topic might be done as a side project at a later time. For simplicity,
we will stick to a 5-D version of the 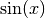 of the previous
section. Let’s declare it with numpy and torch. NumPy arrays will
remain on the CPU and torch tensor on the GPU.
of the previous
section. Let’s declare it with numpy and torch. NumPy arrays will
remain on the CPU and torch tensor on the GPU.
dimension = 5
integration_domain = [[0, 1]] * dimension
ground_truth = 2 * dimension * np.sin(0.5) * np.sin(0.5)
def f_3(x):
return torch.sum(torch.sin(x), dim=1)
def f_3_np(*x):
return np.sum(np.sin(x))
Now let’s evaluate the integral using the scipy function nquad.
start = time.time()
opts = {"limit": 10, "epsabs": 1, "epsrel": 1}
result, _, details = nquad(f_3_np, integration_domain, opts=opts, full_output=True)
end = time.time()
print("Results:", result)
print("Abs. Error:", np.abs(result - ground_truth))
print(details)
print(f"Took {(end - start) * 1000.0:.3f} ms")
Output: Results: 2.2984884706593016
Abs. Error: 0.0
{'neval': 4084101}
Took 33067.629 ms
Using scipy, we get the result in about 33 seconds on the authors’
machine (this might take shorter or longer on your machine). The integral was computed with
nquad, which on the inside uses the highly adaptive
QUADPACK algorithm.
In any event, torchquad can reach the same accuracy much, much quicker by utilizing the GPU.
N = 37 ** dimension
simp = Simpson() # Initialize Simpson solver
start = time.time()
result = simp.integrate(f_3, dim=dimension, N=N, integration_domain=integration_domain)
end = time.time()
print_error(result, ground_truth)
print("neval=", N)
print(f"Took {(end - start) * 1000.0:.3f} ms")
If you tried this yourself and ran out of CUDA memory, simply decrease 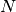 (this will, however, lead to a loss of accuracy).
(this will, however, lead to a loss of accuracy).
Note that we use more evaluation points (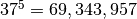 for torchquad vs.
for torchquad vs. 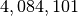 for scipy), given the comparatively simple algorithm.
Anyway, the decisive factor for this specific problem is runtime. A comparison with regard to
function evaluations is difficult, as
for scipy), given the comparatively simple algorithm.
Anyway, the decisive factor for this specific problem is runtime. A comparison with regard to
function evaluations is difficult, as nquad provides no support for a
fixed number of evaluations. This may follow in the future.
The results from using Simpson’s rule in torchquad is:
Output: Results: 2.2984883785247803
Abs. Error: 0.00000000e+00
Rel. Error: 0.00000000e+00
neval= 69343957
Took 162.147 ms
In our case, torchquad with Simpson’s rule was more than 300 times faster than
scipy.integrate.nquad. We will add
more elaborate integration methods over time; however, this tutorial should
already showcase the advantages of numerical integration on the GPU.
Reasonably, one might prefer Monte Carlo integration methods for a 5-D problem. We might add this comparison to the tutorial in the future.
Using different backends with torchquad
This section shows how to select a different numerical backend for the quadrature. Let’s change the minimal working example so that it uses Tensorflow instead of PyTorch:
import tensorflow as tf
from torchquad import MonteCarlo, set_up_backend
# Enable Tensorflow's NumPy behaviour and set the floating point precision
set_up_backend("tensorflow", data_type="float32")
# The integrand function rewritten for Tensorflow instead of PyTorch
def some_function(x):
return tf.sin(x[:, 0]) + tf.exp(x[:, 1])
mc = MonteCarlo()
# Set the backend argument to "tensorflow" instead of "torch"
integral_value = mc.integrate(
some_function,
dim=2,
N=10000,
integration_domain=[[0, 1], [-1, 1]],
backend="tensorflow",
)
As the name suggests, the set_up_backend function configures a numerical
backend so that it works with torchquad and it optionally sets the floating
point precision.
For Tensorflow this means in our code it enables
NumPy behaviour
and configures torchquad so that it uses float32 precision when initialising
Tensors for Tensorflow.
More details about torchquad.set_up_backend() can be found in its
documentation.
To calculate an integral with Tensorflow we changed the backend argument of
the integrate method.
An alternative way to select Tensorflow as backend is to set the
integration_domain argument to a tf.Tensor instead of a list.
The other code changes we did, for example rewriting the integrand,
are not directly related to torchquad.
To use NumPy or JAX we would analogously need to change the two backend
arguments to "numpy" resp. "jax" and rewrite the integrand function.
Computing gradients with respect to the integration domain
torchquad allows fully automatic differentiation. In this tutorial, we will show how to extract the gradients with respect to the integration domain with the PyTorch backend. We selected the composite Trapezoid rule and the Monte Carlo method to showcase that getting gradients is possible for both deterministic and stochastic methods.
import torch
from torchquad import MonteCarlo, Trapezoid, set_up_backend
def test_function(x):
"""V shaped test function."""
return 2 * torch.abs(x)
set_up_backend("torch", data_type="float64")
# Number of function evaluations
N = 10000
# Calculate a gradient with the MonteCarlo integrator
# Define the integrator
integrator_mc = MonteCarlo()
# Integration domain
domain = torch.tensor([[-1.0, 1.0]])
# Enable the creation of a computational graph for gradient calculation.
domain.requires_grad = True
# Calculate the 1-D integral by using the previously defined test_function
# with MonteCarlo; set a RNG seed to get reproducible results
result_mc = integrator_mc.integrate(
test_function, dim=1, N=N, integration_domain=domain, seed=0
)
# Compute the gradient with a backward pass
result_mc.backward()
gradient_mc = domain.grad
# Calculate a gradient analogously with the composite Trapezoid integrator
integrator_tp = Trapezoid()
domain = torch.tensor([[-1.0, 1.0]])
domain.requires_grad = True
result_tp = integrator_tp.integrate(
test_function, dim=1, N=N, integration_domain=domain
)
result_tp.backward()
gradient_tp = domain.grad
# Show the results
print(f"Gradient result for MonteCarlo: {gradient_mc}")
print(f"Gradient result for Trapezoid: {gradient_tp}")
The code above calculates the integral for a 1-D test-function test_function() in the [-1,1] domain and prints the gradients with respect to the integration domain.
The command domain.requires_grad = True enables the creation of a computational graph, and it shall be called before calling the integrate(...) method.
Gradients computation is, then, performed calling result.backward().
The output of the print statements is as follows:
Gradient result for MonteCarlo: tensor([[-1.9828, 2.0196]])
Gradient result for Trapezoid: tensor([[-2.0000, 2.0000]])
Speedups for repeated quadrature
Compiling the integrate method
To speed up the quadrature in situations where it is executed often with the
same number of points N, dimensionality dim, and shape of the integrand
(see the next section for more information on integrands),
we can JIT-compile the performance-relevant parts of the integrate method:
import time
import torch
from torchquad import Boole, set_up_backend
def example_integrand(x):
return torch.sum(torch.sin(x), dim=1)
set_up_backend("torch", data_type="float32")
N = 912673
dim = 3
integrator = Boole()
domains = [torch.tensor([[-1.0, y]] * dim) for y in range(5)]
# Integrate without compilation
times_uncompiled = []
for integration_domain in domains:
t0 = time.perf_counter()
integrator.integrate(example_integrand, dim, N, integration_domain)
times_uncompiled.append(time.perf_counter() - t0)
# Integrate with partial compilation
integrate_jit_compiled_parts = integrator.get_jit_compiled_integrate(
dim, N, backend="torch"
)
times_compiled_parts = []
for integration_domain in domains:
t0 = time.perf_counter()
integrate_jit_compiled_parts(example_integrand, integration_domain)
times_compiled_parts.append(time.perf_counter() - t0)
# Integrate with everything compiled
times_compiled_all = []
integrate_compiled = None
for integration_domain in domains:
t0 = time.perf_counter()
if integrate_compiled is None:
integrate_compiled = torch.jit.trace(
lambda dom: integrator.integrate(example_integrand, dim, N, dom),
(integration_domain,),
)
integrate_compiled(integration_domain)
times_compiled_all.append(time.perf_counter() - t0)
print(f"Uncompiled times: {times_uncompiled}")
print(f"Partly compiled times: {times_compiled_parts}")
print(f"All compiled times: {times_compiled_all}")
speedups = [
(1.0, tu / tcp, tu / tca)
for tu, tcp, tca in zip(times_uncompiled, times_compiled_parts, times_compiled_all)
]
print(f"Speedup factors: {speedups}")
This code shows two ways of compiling the integration.
In the first case, we use integrator.get_jit_compiled_integrate,
which internally uses torch.jit.trace to compile performance-relevant code
parts except the integrand evaluation.
In the second case we directly compile integrator.integrate.
The function created in the first case may be a bit slower,
but it works even if the integrand cannot be compiled and we can re-use it
with other integrand functions.
The compilations happen in the first iteration of the for loops and in the
following iterations the previously compiled functions are re-used.
With JAX and Tensorflow it is also possible to compile the integration.
In comparison to compilation with PyTorch,
we would need to use jax.jit or tf.function instead of
torch.jit.trace to compile the whole integrate method.
get_jit_compiled_integrate automatically uses the compilation function
which fits to the numerical backend.
There is a special case with JAX and MonteCarlo:
If a function which executes the integrate method is compiled with jax.jit,
the random number generator’s current PRNGKey value needs to be an input and
output of this function so that MonteCarlo generates different random numbers
in each integration.
torchquad’s RNG class has methods to set and get this PRNGKey value.
The disadvantage of compilation is the additional time required to compile or
re-compile the code,
so if the integrate method is executed only a few times or certain arguments,
e.g. N, change often, the program may be slower overall.
Reusing sample points
With the MonteCarlo and composite Newton Cotes integrators it is possible to
execute the methods for sample point calculation, integrand evaluation and
result calculation separately.
This can be helpful to obtain a speedup in situations where integration happens
very often with the same integration_domain and N arguments.
However, separate sample point calculation has some disadvantages:
The code is more complex.
The memory required for the grid points is not released after each integration.
With MonteCarlo the same sample points would be used for each integration, which corresponds to a fixed seed.
Here is an example where we integrate two functions with Boole and use the same sample points for both functions:
import torch
from torchquad import Boole
def integrand1(x):
return torch.sin(x[:, 0]) + torch.exp(x[:, 1])
def integrand2(x):
return torch.prod(torch.cos(x), dim=1)
# The integration domain, dimensionality and number of evaluations
# For the calculate_grid method we need a Tensor and not a list.
integration_domain = torch.Tensor([[0.0, 1.0], [-1.0, 1.0]])
dim = 2
N = 9409
# Initialize the integrator
integrator = Boole()
# Calculate sample points and grid information for the result calculation
grid_points, hs, n_per_dim = integrator.calculate_grid(N, integration_domain)
# Integrate the first integrand with the sample points
function_values, _ = integrator.evaluate_integrand(integrand1, grid_points)
integral1 = integrator.calculate_result(function_values, dim, n_per_dim, hs, integration_domain)
# Integrate the second integrand with the same sample points
function_values, _ = integrator.evaluate_integrand(integrand2, grid_points)
integral2 = integrator.calculate_result(function_values, dim, n_per_dim, hs, integration_domain)
print(f"Quadrature results: {integral1}, {integral2}")
Multidimensional/Vectorized Integrands
If you wish to evaluate many different integrands over the same domain, it may be faster to pass in a vectorized formulation if possible.
Our inspiration for this came from scipy’s own vectorization capabilities e.g., from its fixed_quad method.
As an example, here we evaluate a similar integrand many times for different values of a and b. This is an example that could be sped up by a vectorized evaluation of all integrals:
def parametrized_integrand(x, a, b):
return torch.sqrt(torch.cos(torch.sin((a + b) * x)))
a_params = torch.arange(40)
b_params = torch.arange(10, 20)
integration_domain = torch.Tensor([[0, 1]])
simp = Simpson()
result = torch.stack([torch.Tensor([simp.integrate(lambda x: parametrized_integrand(x, a, b), dim=1, N=101, integration_domain=integration_domain) for a in a_params]) for b in b_params])
Now let’s see how to do this a bit more simply, and in a way that provides signficant speedup as the size of the integrand’s grid grows:
grid = torch.stack([torch.Tensor([a + b for a in a_params]) for b in b_params])
def integrand(x):
return torch.sqrt(torch.cos(torch.sin(torch.einsum("i,jk->ijk", x.flatten(), grid))))
result_vectorized = simp.integrate(integrand, dim=1, N=101, integration_domain=integration_domain)
torch.all(torch.isclose(result_vectorized, result)) # True!
Note
VEGAS does not support multi-dimensional integrands. If you would like this, please consider opening an issue or PR.
Parametric Integration with Variable Domains
Sometimes you need to perform multiple integrations where both the integrand and the integration domain depend on parameters. This is particularly useful in applications where you need to compute integrals for many different parameter values simultaneously.
For example, you might want to compute:
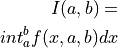
for multiple values of  and
and 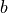 simultaneously.
simultaneously.
Currently, torchquad doesn’t have built-in support for parametric domains, but you can extend the existing integrators to handle this case. Below is an example of how to create a custom integrator that supports batch 1D integration with variable domains:
import torch
from loguru import logger
from autoray import numpy as anp
from autoray import infer_backend
from torchquad import Gaussian
class Batch1DIntegrator(Gaussian):
"""Custom integrator for batch 1D integration with variable domains.
This integrator can compute multiple integrals with different domains
in a single call, providing significant speedup over sequential computation.
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.disable_integration_domain_check = True
def _resize_roots(self, integration_domain, roots):
"""Resize roots for batched integration domains.
Args:
integration_domain: Shape [batch_size, 2] for multiple domains
roots: Shape [N] - the Gaussian quadrature nodes
Returns:
Resized roots with shape [batch_size, N]
"""
if integration_domain.ndim == 1:
# Single domain case - use parent implementation
return super()._resize_roots(integration_domain, roots)
# Batch case
assert roots.ndim == 1
assert integration_domain.ndim == 2
assert integration_domain.shape[-1] == 2
roots = roots.to(integration_domain.device)
# Extract bounds for all domains
a = integration_domain[:, 0:1] # Shape [batch_size, 1]
b = integration_domain[:, 1:2] # Shape [batch_size, 1]
# Broadcast and transform roots for each domain
roots_expanded = roots.unsqueeze(0) # [1, N]
# Transform from [-1, 1] to [a, b] for each domain
out = ((b - a) / 2) * roots_expanded + ((a + b) / 2) # [batch_size, N]
return out
def integrate(self, fn, dim, N, integration_domain=None, backend="torch"):
"""Integrate function over multiple domains in a single call.
Args:
fn: Function to integrate
dim: Must be 1 for this implementation
N: Number of quadrature points
integration_domain: Shape [batch_size, 2] for batch integration
backend: Must be "torch"
Returns:
Tensor of shape [batch_size] with integral results
"""
assert dim == 1
assert backend == "torch"
if integration_domain.ndim == 1:
integration_domain = integration_domain.reshape(1, 2)
batch_size = integration_domain.shape[0]
# Get Gaussian quadrature points and weights
N = self._adjust_N(dim=1, N=N)
roots = self._roots(N, backend, integration_domain.requires_grad)
weights = self._weights(N, dim, backend)
# Resize roots for all domains at once
grid_points = self._resize_roots(integration_domain, roots) # [batch_size, N]
# Evaluate integrand at all points
# Flatten for function evaluation: [batch_size * N, 1]
points_flat = grid_points.reshape(-1, 1)
function_values = fn(points_flat) # [batch_size * N]
# Reshape back to [batch_size, N]
function_values = function_values.reshape(batch_size, N)
# Apply weights and sum for each domain
weighted_values = function_values * weights.unsqueeze(0)
# Scale by domain width and sum
domain_widths = (integration_domain[:, 1] - integration_domain[:, 0]) / 2
results = domain_widths * weighted_values.sum(dim=1)
return results
Now let’s see a concrete example of using this for parametric integration:
# Example 1: Compute multiple integrals in ONE call
# I(a) = integral from 0 to a of x^2 dx = a^3/3
# for a = 1, 2, 3, 4, 5
def integrand(x):
# x has shape [batch_size * N, 1] where N is the number of quadrature points
return x[:, 0] ** 2
# Create multiple integration domains
upper_bounds = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
domains = torch.stack([torch.zeros_like(upper_bounds), upper_bounds], dim=1)
print(f"Integration domains shape: {domains.shape}")
print(f"Domains:\n{domains}")
# Initialize the batch integrator
batch_integrator = Batch1DIntegrator()
# Compute ALL integrals in ONE call - this is the key difference!
results = batch_integrator.integrate(integrand, dim=1, N=50, integration_domain=domains)
# Analytical solution: a^3/3
analytical = upper_bounds ** 3 / 3
print(f"\nResults shape: {results.shape}")
print(f"Numerical results: {results}")
print(f"Analytical results: {analytical}")
print(f"Absolute errors: {torch.abs(results - analytical)}")
Output:
Integration domains shape: torch.Size([5, 2])
Domains:
tensor([[0., 1.],
[0., 2.],
[0., 3.],
[0., 4.],
[0., 5.]])
Results shape: torch.Size([5])
Numerical results: tensor([ 0.3333, 2.6667, 9.0000, 21.3333, 41.6667])
Analytical results: tensor([ 0.3333, 2.6667, 9.0000, 21.3333, 41.6667])
Absolute errors: tensor([9.9341e-09, 7.9473e-08, 1.7764e-14, 6.3578e-07, 1.2716e-06])
The key advantage of this approach is that all integrals are computed in a single vectorized operation, which can provide significant speedups:
# Performance comparison - batch vs sequential
import time
from torchquad import GaussLegendre
# Many domains
n_domains = 500
many_upper_bounds = torch.linspace(0.1, 5.0, n_domains)
many_domains = torch.stack([torch.zeros(n_domains), many_upper_bounds], dim=1)
# Batch computation
start = time.time()
batch_results = batch_integrator.integrate(integrand, dim=1, N=50, integration_domain=many_domains)
batch_time = time.time() - start
# Sequential computation for comparison
standard_integrator = GaussLegendre()
start = time.time()
sequential_results = []
for i in range(n_domains):
result = standard_integrator.integrate(
integrand, dim=1, N=50,
integration_domain=[[0.0, many_upper_bounds[i].item()]]
)
sequential_results.append(result)
sequential_time = time.time() - start
print(f"Computed {n_domains} integrals:")
print(f"Batch time: {batch_time:.4f} seconds")
print(f"Sequential time: {sequential_time:.4f} seconds")
print(f"Speedup: {sequential_time/batch_time:.2f}x")
Output:
Computed 500 integrals:
Batch time: 0.0010 seconds
Sequential time: 0.2289 seconds
Speedup: 228.90x
This approach can be extended to more complex scenarios where both the integrand and the domain depend on parameters. The key insight is that by properly vectorizing the computation, we can achieve significant performance improvements over sequential integration.
Note
This implementation is specifically for 1D integrals. Extending it to higher dimensions would require more careful handling of the grid generation and result calculation.
Multi-GPU Usage
While torchquad doesn’t have a built-in device parameter for selecting specific GPUs, you can effectively use multiple GPUs using standard PyTorch practices and environment variables.
Using CUDA_VISIBLE_DEVICES
The recommended way to control which GPU torchquad uses is through the CUDA_VISIBLE_DEVICES environment variable:
# Use only GPU 0
export CUDA_VISIBLE_DEVICES=0
python your_integration_script.py
# Use only GPU 1
export CUDA_VISIBLE_DEVICES=1
python your_integration_script.py
# Use GPUs 0 and 2
export CUDA_VISIBLE_DEVICES=0,2
python your_integration_script.py
This approach has several advantages:
Clean separation: Each process sees only the specified GPU(s)
No code changes: Your torchquad code remains unchanged
Standard practice: This is the recommended approach in the PyTorch community
Process isolation: Different processes can use different GPUs without interference
Parallel Processing with Multiple GPUs
For compute-intensive workloads that can be parallelized, you can spawn multiple processes, each using a different GPU:
import multiprocessing as mp
import os
import torch
from torchquad import MonteCarlo, set_up_backend
def run_integration_on_gpu(gpu_id, integration_params, result_queue):
"""Run integration on a specific GPU"""
# Set the GPU for this process
os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_id)
# Initialize torchquad
set_up_backend("torch", data_type="float32")
# Your integration code here
mc = MonteCarlo()
result = mc.integrate(
integration_params['fn'],
dim=integration_params['dim'],
N=integration_params['N'],
integration_domain=integration_params['domain'],
backend="torch"
)
result_queue.put((gpu_id, result.item()))
def parallel_integration_example():
"""Example of parallel integration across multiple GPUs"""
# Define your integration parameters
def integrand(x):
return torch.sin(x[:, 0]) + torch.exp(x[:, 1])
integration_params = {
'fn': integrand,
'dim': 2,
'N': 100000,
'domain': [[0, 1], [-1, 1]]
}
# Check available GPUs
available_gpus = list(range(torch.cuda.device_count()))
if not available_gpus:
print("No CUDA GPUs available")
return
print(f"Using GPUs: {available_gpus}")
# Create processes for each GPU
processes = []
result_queue = mp.Queue()
for gpu_id in available_gpus:
p = mp.Process(
target=run_integration_on_gpu,
args=(gpu_id, integration_params, result_queue)
)
p.start()
processes.append(p)
# Collect results
results = {}
for _ in available_gpus:
gpu_id, result = result_queue.get()
results[gpu_id] = result
# Wait for all processes to complete
for p in processes:
p.join()
print("Results from each GPU:")
for gpu_id, result in sorted(results.items()):
print(f" GPU {gpu_id}: {result:.6f}")
return results
Use Cases for Multi-GPU Integration
Parameter Sweeps: Run the same integration with different parameters on different GPUs
Different Integration Methods: Compare multiple integration methods simultaneously
Monte Carlo with Different Seeds: Run multiple Monte Carlo integrations with different random seeds for error estimation
Batch Processing: Process multiple independent integration problems in parallel
Example: Monte Carlo Error Estimation
import subprocess
import numpy as np
def monte_carlo_error_estimation():
"""Estimate integration error using multiple independent Monte Carlo runs"""
# Script content for each GPU process
script_template = '''
import os import torch from torchquad import MonteCarlo, set_up_backend
os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘{gpu_id}’ set_up_backend(“torch”, data_type=”float32”)
- def integrand(x):
return torch.sin(x[:, 0]) + torch.exp(x[:, 1])
mc = MonteCarlo() result = mc.integrate(
integrand, dim=2, N=50000, integration_domain=[[0, 1], [-1, 1]], seed={seed}, backend=”torch”
)
print(result.item()) ‘’’
num_gpus = torch.cuda.device_count() runs_per_gpu = 5
results = [] processes = []
- for gpu_id in range(num_gpus):
- for run in range(runs_per_gpu):
seed = gpu_id * runs_per_gpu + run + 1000 script = script_template.format(gpu_id=gpu_id, seed=seed)
# Launch subprocess process = subprocess.Popen(
[‘python’, ‘-c’, script], stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True
) processes.append(process)
# Collect results for process in processes:
stdout, stderr = process.communicate() if process.returncode == 0:
results.append(float(stdout.strip()))
- else:
print(f”Error in subprocess: {stderr}”)
# Calculate statistics results = np.array(results) mean_result = np.mean(results) std_error = np.std(results) / np.sqrt(len(results))
print(f”Monte Carlo Results from {len(results)} runs:”) print(f” Mean: {mean_result:.6f}”) print(f” Standard Error: {std_error:.6f}”) print(f” 95% Confidence Interval: [{mean_result - 1.96*std_error:.6f}, {mean_result + 1.96*std_error:.6f}]”)
return mean_result, std_error
Best Practices for Multi-GPU Usage
Use CUDA_VISIBLE_DEVICES: This is the cleanest way to control GPU selection
Process-based parallelism: Use
multiprocessingrather than threading for true parallelismMemory management: Each GPU process will have its own memory space
Load balancing: Distribute work evenly across available GPUs
Error handling: Handle cases where specific GPUs might be unavailable or busy
Warning
Avoid using torch.cuda.set_device() within torchquad applications, as this can interfere with torchquad’s internal device management. Always use CUDA_VISIBLE_DEVICES instead.
Custom Integrators
It is of course possible to extend our provided Integrators, perhaps for a special class of functions or for a new algorithm.
import scipy
from torchquad import Gaussian
from autoray import numpy as anp
class GaussHermite(Gaussian):
"""
Gauss Hermite quadrature rule in torch, for integrals of the form :math:`\\int_{-\\infty}^{+\\infty} e^{-x^{2}} f(x) dx`. It will correctly integrate
polynomials of degree :math:`2n - 1` or less over the interval
:math:`[-\\infty, \\infty]` with weight function :math:`f(x) = e^{-x^2}`. See https://en.wikipedia.org/wiki/Gauss%E2%80%93Hermite_quadrature
"""
def __init__(self):
super().__init__()
self.name = "Gauss-Hermite"
self._root_fn = scipy.special.roots_hermite
@staticmethod
def _apply_composite_rule(cur_dim_areas, dim, hs, domain):
"""Apply "composite" rule for gaussian integrals
cur_dim_areas will contain the areas per dimension
"""
# We collapse dimension by dimension
for _ in range(dim):
cur_dim_areas = anp.sum(cur_dim_areas, axis=len(cur_dim_areas.shape) - 1)
return cur_dim_areas
gh=GaussHermite()
integral=gh.integrate(lambda x: 1-x,dim=1,N=200) #integral from -inf to inf of np.exp(-(x**2))*(1-x)
# Computed integral was 1.7724538509055168.
# analytic result = sqrt(pi)